
|
Vergleichende Evaluation von Open-Source-MÜ-Systemen
Bachelorarbeit
Linguistische Informatik
Universität FAU Erlangen-Nürnberg
Ivette Schmid
Prüfer: Prof. Dr. Stefan Evert
Abgabedatum: 29.09.2017
Inhaltsverzeichnis
Tabellenverzeichnis
1 Einführung
"Maschinelle Übersetzung (MÜ) ist eine Anwendung von Computern für die Übersetzung von Texten von einer natürlichen Sprache zu einer anderen." [Hutchins 1986: 15] Sie dient uns in unseren vernetzten, globalen Welt als alltägliche Hilfe. Fremde Kulturen werden greifbarer und Fremde zu Freunden. Der Wunsch nach Vernetzung und die Neugierde auf Neues ist ein tief verwurzeltes Verlangen des Menschen. Die maschinelle Übersetzung, besonders in unserem vernetzten Zeitalter, bietet die Möglichkeit diesen Wusch zu erfüllen. Sie entstammt unter anderem aus der weiterentwickelte Idee, die schon Descartes und Leibniz hatten. Beide wollten mit Hilfe eines numerischen Codes zwischen zwei oder mehreren Sprachen vermitteln und damit eventuell eine universale Sprache entwickeln, die alle lexikalischen Äquivalente aller bekannten Sprachen in der selben Nummernfolge kodiert. [Hutchins 1986: 21] Ihnen ist dies nicht gelungen, doch heutzutage haben fähige Wissenschaftler andere Mittel und Wege gefunden um Bedeutungen von Texten zwischen zwei Sprachen ohne große Verluste zu konvertieren. Wenn im Kontext von maschinellen Übersetzern Sprachen erwähnt wird, so handelt es sich meist entweder um die Ausgangssprache oder die Zielsprache. Mit Ausgangssprache wird immer die Sprache gemeint, welche als Grundlage der Übersetzung dient. Sie ist das original. Die Zielsprache hingegen ist die gewünschte Sprache der Übersetzung. Am Ende soll der Text nach der Verarbeitung in dem MÜ-System in dieser Sprache vorliegen.
Die vorliegende Arbeit dient dem Zweck die kostenfrei zugänglichen Möglichkeiten der maschinellen Übersetzung untereinander zu vergleichen und zu bewerten. Dabei werden exemplarisch MÜ-Systeme und Evaluationsmethoden vorgestellt. Die Arbeit ist dabei in drei grundlegende Abschnitte gegliedert. Die Einführung in die maschinelle Übersetzung, das definieren von Ressourcen und maschinellen Übersetzern von Interesse und der Evaluation dieser. Nach dieser Einleitung in die Arbeit beginnt die Einführung in das Thema "maschinelle Übersetzung", welche das Ziel verfolgt, kurz und knapp einen Überblick über die Geschichte und Entwicklung der maschinellen Übersetzung zu bieten. In der anschließenden Evaluationsvorbereitung werden die verwendeten Korpusressourcen und deren Vorverarbeitung beschrieben. Nach einer ausführlichen Aufführung und Beschreibung der genutzten maschinellen Übersetzer, beginnt der Evaluationsabschnitt, in dem manuelle und maschinelle Evaluationsmethoden genutzt werden um die Übersetzersysteme zu bewerten. Eine nachfolgende Zusammenführung der Evaluationsergebnisse resultiert in abschließenden Gedanken, die die Arbeit abrunden.
2 Geschichte und Entwicklung der Maschinellen Übersetzung
Die Geschichte der Maschinellen Übersetzung umfasst im Jahr 2017 inzwischen eine lange Zeitspanne der Entwicklung. In diesem Kapitel wird versucht einen kurzen Überblick der Entstehungsgeschichte und der Herausbildung heutiger Technik zu bieten. Die hier beschriebenen Fakten stammen vorrangig aus [Hutchins 1986: 1ff, 40ff und 334], weswegen diese nicht bei jedem Aufkommen gesondert gekennzeichnet werden.
Generell kann die Entwicklung der Maschinellen Übersetzung entweder in Perioden, die jeweils etwa einem Jahrzehnt entsprechen, oder in Generationen aufgeteilt werden. Betrachtet man die Perioden so beschreibt die erste Periode den Zeitraum zwischen dem Ende des 2. Weltkrieges und der MIT Konferenz im Jahr 1956. Motiviert wird die Forschung durch die Hoffnung, dass durch die Eliminierung der Sprachbarrieren durch automatische Übersetzungen Frieden gewährleistet werden kann. In diesem, aber auch in anderen Zusammenhängen, glaubte man voller Hoffnung an ein hohes Potential "elektronischer Gehirne". [Hutchins 1986: 11] Die zweite Periode zieht sich bis zum ALPAC Report in den 1960ern. Diese Periode wird geprägt durch die umfassende Unterstützung durch die US Regierung und des Militärs, großem Enthusiasmus und ebenso großer Enttäuschung. Die hoffnungsvolle Stimmung nach vielen Fehlschlägen und kaum Erfolgen wurde durch eine Welle der Desillusionierung gedämpft. [Hutchins 1986: 11] Die Forschung an automatisierter Übersetzung wurde gar als "Reinfall" bezeichnet, die keine Zukunft besäße, da keine der ursprünglichen euphorischen hohen Erwartungen erfüllt werden konnte. Diese Stimmung wurde durch Veröffentlichungen von peinlichen Fehlübersetzungen weiter aufgeheizt. Dies sorgte für eine vermehrte Verspottung dieses Wissenschaftszweiges. [Hutchins 1986: 16] Danach begann die "stille" Periode, in der sich die Forschung auf indirekte Übersetzungssysteme konzentrierte und erste funktionale Systeme sich langsam etablierten. Denn trotz des Spottes setzten sich MÜSysteme, wegen ihrer Praktikabilität selbst bei mäßiger Qualität, über die Jahre hinweg im Alltag fest. Dieser Trend konnte vor allem in der Berufswelt beobachtet werden.
Die vierte Periode begann in den 1970ern mit dem Interesse der Kommission der Europäischen Union an der Maschinellen Übersetzung. Dabei zeigen alle Behörden der Mitglieder der frisch gegründeten Europäischen Union, die durch die Multilingualität ihrer neuen Vereinigung vor viele Probleme gestellt wird, eine Umsetzung des oben erwähnten Trends der offiziellen Einbindung der maschinellen Übersetzung in das alltägliche Berufsleben. Die drängendste Aufgabe war die Vereinheitlichung der vielen monolingualen administrativen, wirtschaftlichen und technischen Dokumentation, die Übersetzungen in alle Sprachen der Gemeinschaft benötigt. [Hutchins 1986: 15] Doch erst 1980 wurde der ursprüngliche Optimismus wieder auferweckt und durch motivierende Arbeiten, wie Abhandlungen über die wissenschaftstheoretische Verankerung der MÜ-Forschung, welche sich vorallem auf die schon funktionierenden Aspekte der maschinellen Übersetzung wie computergestützte Übersetzungsarbeiten konzentrierten, [Wilss 1987] vorangetrieben.
In dieser Zeit begann auch die Inbetriebnahme von Systran, den ersten öffentlich zugänglichen maschinellen Übersetzungssystemen wie METEO, damit auch mit dem Aufkommen kommerziellen Systemen und ersten auf künstlicher Intelligenz basierenden Ansätzen. Im Jahr 1988 wurde die Forschung in dem Gebiet durch statistische maschinelle Übersetzer revolutioniert, welche Übersetzungen nicht mehr nach Regeln sondern nach Wahrscheinlichkeiten in massiven Korpora erstellen. [Stein 2009: 9] Dies läutete die nächste Periode ein. In der heutigen Zeit befinden wir uns in einer nächsten Periode, in der künstliche Intelligenz und neuronale Netzwerke eine immer wichtigere Rolle spielen und es funktionierende neuronale maschinelle Übersetzer gibt. Alte System wurden teilweise zu ausgefeilten Hybrid-MÜ-Systemen aus regelbasierten und statistischen Methoden kombiniert, wobei jedoch simple statistische Übersetzer ebenfalls noch auf dem Markt sind. Zudem wird viel Wert auf die öffentliche und kommerzielle Nutzung im Internet gesetzt um jedem Zugang auf die Rechenleistung massiver Server zu gewährleisten, auf denen die neuronalen maschinellen Übersetzer trainiert wurden.
Man erkennt, dass die Entwicklung schrittweise erfolgt. Erst in wenigen großen, dann mit vielen kleinen Schritten. Betrachtet man heutzutage beispielsweise Bücher von vor etwa 10 Jahren, so haben die beschriebenen Systeme für heute in den meisten Fällen keine Relevanz mehr und dienen nur noch der historischen Dokumentation. Ein Beispiel dafür ist das Buch "Maschinelle Übersetzungssysteme" [Schwanke 1995], welches wegen Hardwarebeschränkungen Nutzern noch empfiehlt elektronische Wörterbücher zu gebrauchen und die ausgewählten Werke, welche zu der Zeit etabliert waren, in keiner Weise mit den aktuellen Systemen übereinstimmen. Doch sind genau solche Bücher garant dafür, dass die Menschheit morgen noch weiß, woraus sich die heutzutage alltägliche Technik entwickelt hat: Aus simplen Wörterbüchern. Aus diesen bildeten sich die erste Generation von MÜ-Systemen heraus: Die automatischen Wörterbücher, welche Texte durch Wort-für-Wort Übersetzung verarbeiteten. Die nächste naheliegende Aufgabe bestand darin die Wörterbuchgröße zu verringern. Um dies zu ermöglichen wurden die Worte von "regelbasierten" MÜSystemen in Stämme und Endungen aufgespalten. Jedoch gibt es dabei viele komplizierte Unregelmäßigkeiten, die bis heute noch nicht zu hundert Prozent in Regeln gefasst werden können, weshalb Systeme immer wieder auf Vollformenwörterbücher zurückgreifen, trotz der dadurch großen zu speichernden Datenmenge. Ein großes Problem, mit welchem jeder Maschineller Übersetzer zu kämpfen hat, ist der Umgang mit unbekannten Worten. Es gibt zwei offensichtliche Möglichkeiten mit dem Problem umzugehen. Die eine ist die Übernahme des originalen Worts aus der zu übersetzenden Sprache in die Zielsprache. Diese Lösung ist jedoch sehr unelegant. Eine anmutigere Art das Problem zu lösen, ist der Versuch das Wort bestmöglich zu analysieren und dann optimal zu übersetzen. Dies ist jedoch nur möglich, wenn mindestens die vorher erwähnte Spaltung in Stamm und Endung vorgenommen wurde. Weitere Probleme, mit denen die Wort-für-Wort Übersetzung zu kämpfen hat, ist die sich unterschei dende Wortreihenfolge der Zielsprache verglichen mit der Ausgangssprache, welche nur durch eine strukturelle Analyse der zu übersetzenden Sprache aufzulösen ist, [Hutchins 1986: 40] und die Tatsache, dass selten eine vollkommene Korrespondenz in dem Vokabular natürlicher Sprachen existiert, sondern es auf ein Ausgangswort mehrere mögliche Wörter in der Zielsprache gibt. [Hutchins 1986: 42] Eine Lösung für dieses Problem ist die Wörter nach Kontext zu sortieren und dann durch den globalen inhaltlichen Rahmen die richtige Bedeutung des Wortes auszuwählen. Eine andere Option sind um den Satzkontext vergrößerte Wörterbücher von je mindestens zwei Nachbarwörtern pro Wort oder die Expansion des Wörterbuches durch semantische Features um durch nach deren Beziehung zueinander das richtige Wort in der Zielsprache zu finden. [Hutchins 1986: 43] Jedes der oben erwähnten Probleme lässt sich weitesgehend umgehen durch den Zusatz einer morphologischen und syntaktischen Analyse in das System. Durch diesen Ansatz entstanden die uns heute bekannten Typen MÜ-Systeme. Die erste Struktur, die so entstanden ist, ist das "direkte" Übersetzungssystem, welches sich ausschließlich auf ein Sprachenpaar konzentriert und sich in seiner Schlichtheit auszeichnet: Die Ausgangsprache wird analysiert, es werden Ausgangssprache-zu-Zielsprache Wörterbücher und Grammatiken beratschlagt und daraufhin das Ergebnis synthetisiert, so dass der ursprüngliche Text nun in der Zielsprache zu lesen ist. Dieses System funktioniert besser je näher die Sprachen zueinander verwandt sind, da davon ausgegangen wird, dass die Wortstellung des Sprachenpaares hauptsächlich die selbe ist und die syntaktische Analyse nur zur Ambiguitätsauflösung gebraucht wird. [Hutchins 1986: 54] Daraus entwickelten sich sowohl die "indirekten" sowie "Transfer-" Systeme.[Schwarzl 2001: 28f] Die "indirekten" Systeme zeichnen sich durch die Nutzung einer Interlingua aus, also einer abstrakten Zwischensprache, um von einer oder mehreren Sprachen in eine oder mehrere andere zu übersetzen. Transfersysteme basieren auf kontextfreien Grammatiken und zeichnen sich darin aus, dass sie die Ausgangssprache analysieren, dann normalisiert in die normalisierte Struktur der Zielsprache transferieren und von dort aus einen Text mit gleichbleibender Bedeutung in der Zielsprache synthetisieren. Daraufhin folgte ein extremer, jedoch sehr vielversprechender Umschwung Richtung statistischer Systeme. Damit begann nach den regelbasierten maschinellen Übersetzern die dritte Generation der Forschung an automatischer Übersetzung. Die ersten Prototypen waren wortbasierte statistische maschinelle Übersetzer, doch bald wurde der Vorteil phrasenbasierter Systeme erkannt, der vorallem bei zum Beispiel englischen Nomen-Nomen Komposita oder deutschen Verbpartikeln besonders groß ist. Im Jahre 2013 wurde die neuronale maschinelle Übersetzung eingeführt und die Mehrheit dieser Systeme nutzt ein Encoder-Decoder Prinzip, wobei der Encoder einen Satz in der Ausgangssprache in einen Vektor bestimmter Länge kodiert und der Decoder aus dem Vektor die Übersetzung in der Zielsprache folgert. [Bahdanau, Cho und Bengio 2015] Dies ist die aktuelle, vierte Generation der maschinellen Übersetzung und einige der im späteren Kapitel vorgestellten Übersetzer sind zu dieser einzuordnen.
3 Evaluationsvorbereitung
Als Hauptressourcen für die für diese Arbeit ausgeführten Experimente dienten die Deutsch – Englischen Sprachpaardaten des Europarl Parallel Korpus [Koehn 2005] und der OpenSubtitles2016 [Lison und Tiedemann 2016] Sammlung. Das erste Korpus ist in formaler Sprache verfasst, das zweite umgangssprachlich. Der Unterschied ermöglicht es möglicherweise divergierendes Verhalten bei unterschiedlichen Sprachtypen festzuhalten. Die Originaldaten wurden für die im späteren Kapitel beschriebenen Experimente angepasst. Das Europarl Parallel Korpus wurde in Trainings- und Testdaten aufgeteilt. Die Testdaten sind pro Sprache die letzten 100 Zeilen des Korpus und die Trainingsdaten beinhalten jeweils den Rest des Textes. Nach dieser Trennung beinhalten die Deutschen Europarl Testdaten 120 Sätze, 2211 Wörter beziehungsweise 15401 Zeichen und die englischen Daten aber lediglich 103 Sätze, dabei aber 2545 Wörter und insgesamt 14697 Zeichen. [CharacterCountOnline 2017] Die Trainingsdaten sind somit alles was nach Abzug der eben genannten Zahlen von dem Original mit 1920209 parallelen "Sätzen", eigentlich bedeutungsgleichen Zeilen, aber nicht Sätze im wortwörtlichen Sinne, und dabei 44548491 Deutschen Wörtern und 47818827 Englischen Wörtern bleibt. [Statmt 2012] Die OpenSubtitles2016 Daten wurden, außer bei Thot als Entwicklungsdaten, nur als Testdaten verwendet. Sie sind ebenfalls pro Sprache 100 Zeilen lang. Der deutsche Teil besteht aus 99 Sätzen, 598 Wörtern oder einfach 2757 Zeichen, während der englische Teil mit 101 Sätze, 682 Wörter oder 2798 Zeichen in jeder Kategorie mehr vorzuweisen hat. [CharacterCountOnline 2017] Obwohl in jedem Sprachteil der selbe Inhalt vermittelt wird, zeigen beide Korpora eine deutliche Divergenz an Textbestandteilen je Sprache und eine offensichtliche Nicht-Beachtung der "ein Satz pro Zeile" Idee. Dass diese Eigenschaft bei natürlich-sprachlichen Daten besteht, ist intuitiv nachvollziehbar, jedoch kann dies auch zu unerwünschten Effekten führen, wie bei der Erstellung von Daten im SGML-Format, welche für einige maschinellen Evaluationen vonnöten sind. Um die eben erwähnten SGML-Daten zu erstellen, muss erst eine Referenz im SGM-Format darliegen. Diese benötigte Umwandlung wurde mit Hilfe des in den elektonischen Daten beigelegten, selbstverfassten Skripts "sgmthisplease.py" an den Testdaten aus dem Europarl Parallel Korpus durchgeführt und für entsprechende Einsatzfälle aufbewahrt.
4 Die betrachteten Systeme
Dieser Abschnitt beleuchtet den Auswahlprozess der betrachteten Maschinellen Übersetzer Systeme und deren individuellen Merkmale. Grundvoraussetzung für alle Übersetzer war, das sie ein eigenständiges System darstellen. Diese Auflistung soll keinen Marktüberblick bieten, sondern nur die für die in dieser Arbeit genutzten, unter beschriebener Eingrenzung zufällig gewählten Beispiele aus der Welt der maschinellen Übersetzung, darstellen.
4.1 OpenSource
"Open-Source-Software ist Software mit Quellcode, die jeder inspizieren, modifizieren und verbessern kann." [Opensource 2017] Die kostenlose, öffentliche Zugänglichkeit von Daten ist moralisch betrachtet wertvoll und um diese zu fördern, ist es wichtig diese in regelmäßigen Abständen genauer zu betrachten und in den Kontext anderer Daten selben Inhalts in nicht-open-source zu stellen. Die Anzahl der in diesem Vergleich verwendeten Open-Source-Systeme ist bedauerlicherweise relativ gering. Hauptgrund dafür ist die Voraussetzung an den Übersetzer ein autonomes MÜ-System zu sein und nicht nur beispielsweise ein Dekodierer (Decoder) von vortrainierten Sprachmodellen, wie sie üblicherweise in dem Open-Source-Bereich aufzufinden sind. Ein anderer Grund für den Mangel an Open-Source-Systemen ist die gewählte Beschränkung auf das Sprachenpaar Deutsch-Englisch. Dadurch fallen zum Beispiel alle altbekannten regelbasierten Systeme, die nur sehr nah verwandte Sprachen übersetzen, wie Apertium weg.
4.1.1 Thot
Thot ist ein Open-Source statistisches maschinelles Übersetzungssystem, welches phrasen-basiert arbeitet. [Ortiz-Martínez 2014] Neben der Option manuell jeden Schritt von Tokenisierung des Korpus bis zur Übersetzung auszuführen, stellt das System die Möglichkeit zur Verfügung den Vorgang automatisiert durchführen zu lassen. Letztere Option wurde hier verwendet.
Die Übersetzungen wurden durch ein auf den vorbereiteten Europarl Trainingskorpus trainiertem Modell erstellt. Als Entwicklungsdaten wurden außerdem die OPUS-Testdaten zur Verfügung gestellt. Die Erstellung eines Deutsch – Englischen Modells dauerte unter diesen Voraussetzungen etwa eine Woche, das Übersetzen nur wenige Minuten. Trotz wochenlangem Experimentieren mit verschiedenen Parametern war es leider nicht möglich eine Englisch – Deutsch Übersetzung durchzuführen, da das Training in jedem Durchlauf irgendwann wegen einem "Segmentation Error" abgebrochen wurde. Der Grund, welcher sich herauskristallisierte, ist die in dem vorherigen Kapitel erwähnte Inkonsistenz bezüglich der "ein Satz pro Zeile" Idee. Da in den Europarl Trainingsdaten das Englische weniger Sätze hat als das Deutsche kann eine Zuordnung nicht für alle deutschen Sätze stattfinden, wodurch es zu dem oben genannten Fehler kommt. Die einzige Möglichkeit dieses Problem zu beheben, wäre die Erstel6 lung einer neuen Übersetzung, die das Prinzip "ein Satz pro Zeile" durchgehen beachtet, jedoch würde dies den Rahmen dieser Arbeit sprengen und ist auch nicht Sinn und Zweck der Sache.
Es ist anzunehmen, dass die Evaluationsergebnisse dieses Übersetzers schlechter sein werden als die der anderen Systeme, da dieses System als einziges auf dem benutzten Computer trainiert wurde und deshalb vermutlich die geringsten Trainingsdaten zur Modellerstellung zur Verfügung hatte und zudem die erwähnte Zuordnungsschwierigkeit bei der Englisch – Deutsch Übersetzung eventuell auch in der Deutsch – Englisch Übersetzung beim Trainieren Chaos gestiftet hat, auch wenn dies nicht sicher bestimmbar ist. Dies darf bei der Betrachtung der Evaluationsergebnisse nicht vergessen werden.
4.1.2 OpenNMT
OpenNMT ist ein Open-Source neuronales maschinelles Übersetzungssystem. [Klein u.a. 2017] Es bietet neben der standardmäßigen Modellerstellung und Übersetzung viele weitere Optionen an, welche hier jedoch nicht benutzt wurden und weswegen nicht weiter auf sie eingegangen wird.
Die Übersetzungen, die mit OpenNMT erstellt wurden, basieren auf einem vortrainiertem Modell, da der Versuch ein eigenes Modell auf dem vorbereitetem Trainigsteil des Europarl Parallel Korpus zu erstellen daran scheiterte, dass das Trainieren dieses Modells, wenn es die Geschwindigkeit beibehalten hätte, die es während einer Woche Training aufzeigte, auf dem benutzten Computer über 16000 Tage, also wortwörtlich mehrere Jahre, benötigt hätte. Diese enorme Zahl lässt sich hauptsächlich dadurch erklären, dass kaum CPU und RAM zu Verfügung standen, da parallel dazu das oben erwähnte System trainiert wurde, und andererseits OpenNMT darauf ausgelegt ist, die GPU zu benutzen, auf die trotz Triber Update kein Zugriff erstellt werden konnte. Letzteres liegt aber vermutlich daran, dass ein Laptop benutzt wurde und kein Server oder DesktopPC. Mit Hilfe des vortrainierten Modells war es aber möglich sehr leicht und schnell die gewünschten Übersetzungen generieren zu lassen.
4.1.3 Moses
Moses ist ein Open-Source statistisches maschinelles Übersetzungssystem, welches je nach Wunsch phrasen-basiert, syntaktisch oder faktorisiert arbeitet. [Koehn 2017]
Die Übersetzungen wurden jedoch nicht auf einem selbst trainierten System erstellt, sondern auf der vortrainierten Version der Universität Edinburgh [Machine Translation Group 2017], welche als freier Online Dienst zur Verfügung steht. Dies geschah einerseits da eine nicht ausfindig machbare Abhängigkeit auf dem Computer, auf dem das Training stattfinden sollte, nicht gegeben war und somit das Übersetzersystem nicht ohne Neuinstallation und dann hoffentlich richtigen Abhängigikeiten zum Laufen gebracht werden konnte, andererseits weil dieses System somit als Bindeglied zwischen den vorgestellten Open-Source-Systemen und den Online Diensten, welche in den nächsten Abschnitten vorgestellt werden, dienen kann.
4.2 Freie Online Dienste
Um die Open-Source-MÜ-Syteme in Kontext zu setzen wurden die folgenden Systeme ebenfalls evaluiert. Es wurden ausschließlich freie Online Übersetzer ausgewählt. Diese Auswahl lässt sich durch den Anspruch nach kostenfreier Übersetzung, wie es auch bei den Open-Source-Systemen der Fall ist, und dem Wunsch nach eigenständigen Systemen erklären. Da diese Systeme nicht Open-Source sind, sind außerdem keine frei zugänglichen offline Anwendung dieser Systeme aufzufinden, wodurch die Beschränkung auf die Online Dienste weiter unterstützt wird.
4.2.1 Google Übersetzer
Google Übersetzer ist ein Neuronales Maschinelles Übersetzungssystem mit einem eigenen Übersetzersystem namens GNMT (Google Neural Machine Translation), welches sich ursprünglich aus einem phrasen-basierten Übersetzer entwickelt hat. [Le und Schuster 2016]
Bei dem Übersetzen der vorbereiteten Texte gab es ein voraussehbares Problem: Der Google Übersetzer hat eine Begrenzung auf 5000 Zeichen pro Übersetzung. Wenn man daher den ganzen zu übersetzenden Text einfügt, wird der Text für die Übersetzung bei Zeichen Nummer 5000 unterbrochen. Dabei wird weder auf Satz- noch Wortgrenzen geachtet. Das heißt es entsteht an der Bruchstelle eine intern unvermeidbare Fehlerquelle, die nur durch manuellen Eingriff verhindert werden kann oder durch ein externes Skript, welches einen zu übersetzenden Textabschnitt auf maximal 5000 Zeichen begrenzt, wenn aber dabei Sätze zerstört werden würden auf noch weniger Zeichen begrenzt und den Rest für den nächsten Teil aufbewahrt. Das gerade erwähnte theoretisch mögliche Skript wurde für die erstellten Übersetzungen nicht verwendet, da die "Weiterübersetzen" Taste auf der Website verwendet wurde um den ganzen Text zu übersetzen. Eine weitere praktische Möglichkeit, die auf der Google Übersetzer Website geboten wird, ist die Kopierfunktion um die Übersetzung ohne sie vorher manuell markieren zu müssen, kopieren zu können um sie in die Zieldatei einfügen zu können.
4.2.2 Microsoft Übersetzer
Microsoft Übersetzer [Bing 2017] ist ein statistischer maschineller Übersetzer, dessen beworbene neuronale Komponente nur für Übersetzungen der gesprochenen Sprache zugänglich ist oder über einen bestimmten Aufruf der "Text API". [Microsoft 2017] Da die Web-Version für die Experimente genutzt wurde und nicht offengelegt wird, welcher API-Aufruf von dem Übersetzer aufgerufen wird, kann leider nicht genau angegeben werden, welche Art der Übersetzung genutzt wurde. Jedoch wird sich dies spätestens in der Evaluierung herauskris8 tallisieren, da die statistische Übersetzung nicht annähernd so gute Ergebnisse liefern kann wie die neuronale. Dies ist so, weil das neuronale System vollständige Sätze betrachtet und nicht nur einige Wörter lange Phrasen wie bei der statistische Methode üblich. [Microsoft 2017]
Der ursprüngliche Text muss vor seiner Übersetzung mit Microsoft Übersetzer genauso wie bei Google Übersetzer gespalten werden, da auch dieser Übersetzer eine Anzahl von 5000 Zeichen pro Übersetzungstätigkeit zulässt. Da Microsoft Übersetzer jedoch im Gegensatz zu dem Google Übersetzer keine "Weiterübersetzen" Taste besitzt, muss die Trennung manuell oder durch ein externes Skript erfolgen. Die entstandenen Übersetzungen basieren auf manueller Erstellung von Textabschnitten. Dabei wurde darauf geachtet, dass Wörter, die am Ende des vorherigen Abschnittes abgeschnitten wurden, in dem neuen Abschnitt nochmals übersetzt und dann im Endergebnis, also bei der Zusammenführung der einzelnen übersetzten Textabschnitte, ersetzt wurden.
4.2.3 SDL*FreeTranslation
SDL*FreeTranslation.com [SDL 2017] ist ein statistischer maschineller Übersetzer. [SDL Plc 2017] Zur Übersichtlichkeit wird er im Laufe dieser Arbeit meistens als SDL Übersetzer oder einfach SDL adressiert. Eine Besonderheit dieses Übersetzers ist die Einbindung neuronaler Komponenten in das statistische System um dieses zu verbessern. [Gispert, Iglesias und Byrne 2015]
Die Übersetzungen wurden hier auf die selbe Art und Weise erstellt wie mit dem Microsoft Übersetzer. Die Webseite bietet Übersetzung von ganzen Dateien an, diese Funktion konnte für diese Arbeit jedoch nicht genutzt werden, da die eingefügten Dateien angeblich beschädigt seien und deswegen nicht hochladbar waren. Die maximale Anzahl an Text, die der Übersetzer auf einmal übersetzt sind 4500 Zeichen.
4.2.4 SYSTRANet
SYSTRANet [SYSTRAN 2017a] ist ein hybrid maschinelles Übersetzersystem aus regelbasierten und statistischen Komponenten. [SYSTRAN 2017b]
Die Übersetzungen werden bei diesem Übersetzer auf 10001 Zeichen limitiert. Dies ist eine doppelt so große Anzahl an Zeichen als bei dem Google Übersetzer und Microsoft Übersetzer, jedoch musste auch hier der Text manuell in passende Abschnitte getrennt werden. Es wurde nach dem selben Prinzip vorgegangen wie in dem Abschnitt zu dem Microsoft Übersetzer beschrieben.
4.2.5 PNMT
Pure Neural Machine Translation [SYSTRAN 2017d], kurz PNMT, wird als die offizielle OpenNMT Demo angegeben und ist ein neuronaler maschineller Übersetzer basierend auf dem künstlichen neuronalen Netzwerk, welches OpenNMT zur Verfügung stellt. [SYSTRAN 2017c]
Bei der Arbeit mit dem PureNMT Übersetzer ist man beschränkt auf 2000 Zeichen pro Übersetzung, aber da es sich um eine Demo handelt ist dies kein 9 Kritikpunkt. Eine einzigartige Funktion ist die Wahl von einem Übersetzungsprofil. Für die erstellten Übersetzungen wurde die Grundeinstellung, welche einem formalen Profil entspricht, genutzt. Diese Entscheidung entspringt der Überlegung, dass der Thot Übersetzer, welcher als einziger mit den vorbereiteten Daten trainiert wurde, sehr formale Sprache beinhaltet, und damit die Übersetzungsqualität unterschiedlicher Texte zwischen den Übersetzern nicht zu sehr divergiert. Ebenfalls sehr interessant sind die möglichen zusätzlichen Übersetzungsoptionen, die die Benutzerfreundlichkeit des Übersetzers erhöhen, jedoch nicht wie der Name suggeriert die Übersetzung beeinflusst, weswegen nicht weiter darauf eingegangen werden wird.
4.2.6 DeepL
Der DeepL Übersetzer [DeepL 2017a] ist ein im August 2017 gestarteter neuronaler maschineller Übersetzer, der sich aus der bekannten Übersetzungssuchmaschine Linguee entwickelt hat. [DeepL 2017b]
Die Übersetzungen sind genauso wie bei dem Google und Microsoft Übersetzer auf jeweils 5000 Zeichen begrenzt. Der zu übersetzende Text wurde nach der gleichen Herangehensweise wie bei dem Microsoft Übersetzter getrennt und übersetzt. Dementsprechend mussten auch hier die die Grenzen individueller Sätze betrachtet werden und verschiedenen Teile der Übersetzung manuell zusammengeführt werden.
5 Evaluation
Bei der Evaluation von MÜ-Systemen soll die Qualität der Übersetzung verglichen werden. Andere Aspekte wie "Einbettung in eine Benutzerumgebung", "Benutzerfreundlichkeit", "Anpassungs- und Installationskosten", sowie "laufende Kosten" [Luckhardt und Zimmermann 1991: 9] werden bei der Bewertung nicht beachtet, da diese entweder in dem vorherigen Kapitel angesprochen kurz wurden oder wie bei den Kosten, nicht relevant sind, da nur für den Benutzer kostenlose Systeme getestet wurden. Dabei stellt sich einem die Frage an welchen Kriterien, man eine gute Übersetzung festmachen kann. Generell wird eine gute Übersetzung dadurch definiert, dass der Text in der Zielsprache ein Äquivalent des Textes in der Ausgangssprache ist. [Schwarzl 2001: 85] Diese Gleichwertigkeit von Übersetzungen, egal ob menschlich oder maschinell angefertigt, kann an drei grundlegenden Punkten festgemacht werden: der Genauigkeit beziehungsweise der Texttreue den Inhalt betreffend, der Verständlichkeit besser gesagt der Leserlichkeit, also in wie fern der Text grammatikalisch richtig erfasst wurde und dadurch dem Leser das Lesen und Verstehen des Textes erleichtert wird, und dem Stil, welcher in der Zielsprache dem der Ausgangssprache entsprechen sollte. [Schwarzl 2001: 87] Die im vorherigen Kapitel vorgestellten Maschinellen Übersetzer werden nun mithilfe einiger möglicher Evaluationsmethoden bewertet. In Zuge dessen werden die verschiedenen Evaluationsarten und deren Vor- und Nachteile genauer beschrieben. Dabei wird klar zwischen manuellen und maschinellen Methoden unterschieden. Jedoch wird in beiden Bereichen nur ein kleiner Einblick in die divergierenden Möglichkeiten der Qualitätsbewertung maschineller Übersetzung gegeben. Außerdem ist festzuhalten, dass dies eine "Black-Box-Evaluation" [EuroMatrix 2007: 11] ist, also die MÜ-Systeme so genommen werden, wie sie sind, die Zwischenprodukte nicht betrachtet werden und nur Input und Output des Systems von Interesse sind.
5.1 Manuelle Evaluation
Um die Qualität einer Übersetzung zu erfassen existieren im Bereich der manuellen Evaluation zwei grundlegende Arten der Qualitätsbestimmung: Die Numerische Evaluation unter die beispielhaft das Fehlerzählen, das Four Scale Rating und das Two Scale Rating (für den Benchmark Test) fallen und die NichtNumerische Evaluation, welche unteranderem den Benchmark Test, Test Suite und die Evaluation durch Rückübersetzung umfasst. Die Numerische Evaluation zeichnet sich durch die Umkodierung von Sprache in Zahlen, welche eine Aussage über die Qualität des übersetzten Textes treffen, aus. Um mit der nicht-numerischen Methode, welche sich durch kontinuierlichen Vergleich des Ausgangstextes mit dem Original auszeichnet, eine statistisch auswertbare ZIffer, welche für ein Qualitätsranking benötigt wird, zu erhalten, wird in einem vorherigen Schritt eine numerische Evaluation des übersetzten Textes beziehungsweise einzelner Textabschnitte benötigt. [Schwarzl 2001: 89] Ausgenommen der Rückübersetzung werden in dieser Arbeit alle erwähnten Evaluationsarten experimentell ausgeführt.
5.1.1 Four Scale Evaluation der Systeme
Das Four Scale Rating untersucht die Verständlichkeit beziehungsweise Leserlichkeit der Übersetzungen. Dabei reicht die Skala von "sehr gut verständlich" zu "komplett unleserlich". Diese Skala und die Unterteilung in vier Punkte wurde Schwarzl [2001: 92] entnommen und die von den Testpersonen genutzte Skala geht aus der Übersetzung dieser hervor. Um jedoch intuitive Ergebnisgraphen zu erhalten, wurde die Skala rotiert, so dass im Gegensatz zur traditionellen Herangehensweise nun ein hoher Wert auch eine hohe Qualität bedeutet und ein niedriger eine niedrige. Der Wert 1 steht für "unverständlich". Selbst bei dem betrachten des umliegenden Kontextes kann die Bedeutung des Satzes nicht erraten werden. Eine 2 erlangen alle Sätze, die erst nach längerer Betrachtung einen Sinn ergeben zu scheinen. Diese Sätze enthalten teilweise schwere Ausdruck- und Grammatikfehler. Sätze, die generell verständlich sind, aber trotzdem einige Fehler aufweisen, werden mit der Zahl 3 gekennzeichnet. Den Wert 4 bekommen nur klar verständliche Texte ohne Fehler zugewiesen. Die Evaluation wird simpel gehalten und es wird nicht zwischen einer Evaluation bezüglich der Genauigkeit also dem Informationserhalt und der Verständlichkeit also Grammatikalität unterschieden, wie es beispielsweise in der Versuchsreihe von [Schwarzl 2001: 92] getan wurde. Diese Art der manuellen Evaluation benötigt eine große Menge an Testpersonen um ein repräsentatives Ergebnis liefern zu können. Da diese Evaluation mit nur vier Testern durchgeführt wurde, welche allesamt Deutsch jedoch nicht Englisch als Muttersprache besitzen, werden die hier dargestellten Ergebnisse nicht denen einer groß angelegten Studie entsprechen. Trotz allem bieten sie einen Einblick, in welche Richtung die Qualität der getesteten Übersetzer geht. Die Evaluation wurde mit 4 Texten durchgeführt. Einmal mit fünf Sätzen aus dem Europal Parallel Korpus in Englisch, welche aus dem Deutschen übersetzt wurden. Ein zweites Mal in der selben Sprache fünf Sätze aus der OpenSubtitles2016 Sammlung. Der dritte Text besteht wieder aus fünf Sätzen des Europarl Parallel Korpus nur diesmal auf Deutsch. Und der letzte Text ist das eben beschriebene Pendant zu dem zweiten Text. Die Tabellen zeigen die zusammengefassten gerundeten Werte der Bewertungen.

Tabelle 1: Four Scale Rating DE-EN Text1
Die Ergebnisse des ersten Textes zeigen, dass im Durchschnitt alle Systeme über alle Sätze mit dem Durchschnittswert 3 und nur einmal 2 pro Satz eine gute Leistung vollbringen. Die 2 lässt sich dadurch erklären, dass die meisten Systeme Schwierigkeiten damit hatten, die Bezüge zwischen den Worten in dem Satz richtig zu analysieren. Die besten Werte bei dem Satz erzielten die neuronalen MÜ-Systeme PureNMT, OpenNMT und DeepL. Zwischen den Systemen über alle Sätze sind diese Systeme ebenfalls vorne, wobei jedoch nur OpenNMT und DeepL die volle Punktzahl erlangen und OpenNMT so gut abschneidet, wie die Mehrheit der Systeme. SYSTRANet und Thot liefern bei diesem Text mit Abstand die schlechteste Qualität.

Tabelle 2: Four Scale Rating DE-EN Text2
Der zweite Text ist umgangssprachlich verfasst, wodurch Google Übersetzer seine Stärke nutzen kann und den besten Wert erreichen kann. DeepL ist ebenfalls Spitzenreiter. Den niedrigsten Wert erzielt Thot, was jedoch an den genutzten Trainingsdaten liegt, welche keinen Fokus auf die Umgangssprache besitzen. Schwierigkeiten hatten die MÜ-Systeme vor allem mit dem dritten Satz, welcher zwei aneinandergereihte Hauptsätze durch ein "und" verknüpft. Nur DeepL und Microsoft Übersetzer produzieren dabei einen gut lesbaren Satz.

Tabelle 3: Four Scale Rating EN-DE Text3
Die Tester bewerteten die deutschen Texte generell konsistenter als die englischen. Ein Interessanter Hinweis darauf, dass eine solche Evaluation vor allem mit Muttersprachlern Sinn macht, da selbst wenn Bewertungen abweichen, der Unterschied zwischen den gegebenen Werten nicht so groß ist wie bei der Meinungsäußerung zu nicht-muttersprachlicher Daten. Durch die Sicherheit in der Sprache sind die Werte generell niedriger angesetzt worden. Nur DeepL gelingt es eine 4, also "sehr gut", zu holen. Jedoch sind vier Systeme "schlecht", aber es ist bei diesem Text in keinem Gesamtdurchschnitt eine "unleserlich"-Bewertung vorhanden. Letztere Tatsache lässt sich eventuell auf das Fehlen des Thot Übersetzters führen, da dieser als einziger in dem englischen Texten eine "unleserlich" Gesamtbewertung erhalten hat. Die Erklärung, warum Thot hier fehlt, kann aus dem Abschnitt zu diesem Übersetzer im vorherigen Kapitel gelesen werden, weswegen hier nicht weiter darauf eingegangen wird.

Tabelle 4: Four Scale Rating EN-DE Text4
Auch im Deutschen glänzen Google und DeepL mit ihren Kenntnissen der Umgangssprache. Besonders schlecht schneidet OpenNMT in diesem Experiment ab. Dies liegt hauptsächlich an dem Fehlen von Vokabular. Wenn dieses nicht bekannt war, wurde es statt eine Umschreibung oder ähnliches zu versuchen, mit dem Tag '<unk>' gekennzeichnet, welches einen guten Lesefluss stark einschränkt.

Tabelle 5: Four Scale Rating Übersicht
Zusammenfassend lässt sich sagen, dass Thot mit Abstand die schlechteste Übersetzungsqualität geliefert hat. Jedoch wurde dies schon in der einleitenden Beschreibung dieses MÜ-Systems befürchtet und dies ist nur die Bestätigung dafür. OpenNMT schneidet auch schlecht ab, was jedoch hauptsächlich der schlechten Qualität der Übersetzung von Englisch nach Deutsch verschuldet ist. Die besten Übersetzer sind die, die gute Leistungen bei formalen wie auch umgangssprachlichen Texten liefern können. In dieser Auswahl an Programmen sind es die zwei Onlinedienste Google Übersetzer und DeepL. Trotz dem teilweise verbleibenden schlechten Ruf von maschinellen Übersetzern in unserer Gesellschaft, liefern alle Systeme im Mittel ein "gutes" Ergebnis.
5.1.2 Auf Two Scale Rating basierender Benchmark Test
Es wird die selbe Definition des Benchmark Test verwendet wie in [Schwarzl 2001: 97]. Dieser Test wird zu der Evaluation einzelner grammatikalischer Phänomene verwendet. Da es bei diesem Qualitätstest untersucht wird, ob das jeweils betrachtete maschinelle Übersetzungssystem ein grammatikalisches Element in der Übersetzung richtig umsetzen kann oder nicht, ist ein Four Scale Rating, welches in dem vorausgehenden Test genutzt wurde, unnütz. [Schwarzl 2001: 98] Es wird stattdessen ein simples 2 Scale Rating verwendet: Einem Satz wird immer dann ein Punkt verliehen, wenn das grammatikalische Merkmal, welches betrachtet wird, richtig übersetzt wurde. Wenn es falsch umgesetzt wurde, gibt es jedoch keinen Punkt. [Schwarzl 2001: 98] Für den Benchmark Test wird im Anschluss pro Merkmal die Summe der erreichten Punkte gebildet und mit der zu erreichbaren Punktzahl verglichen. Bei der Betrachtung der einzelnen Sätze, geht es tatsächlich ausschließlich nur um das eine grammatikalische Merkmal, alle anderen Fehler sind irrelevant und sollen die Punktevergabe nicht beeinflussen. Wenn es Unklarheiten bei der Bewertung der Umsetzung der grammatikalischen Merkmale gibt, dürfen keine halben Punkte oder Teilpunkte vergeben werden, da sonst der Vergleich der Systeme mathematisch nicht mehr zuverlässig ist. Eine komplett korrekte Bewertung ist so manchmal kaum zu erreichen, da manche Elemente für den einen Tester schon richtig sind, während sie für einen anderen Menschen, mit einem anderen Sprachgefühl, noch Fehler sind. Da diese Evaluation nicht durch einen professionellen Linguisten durchgeführt wurden, werden vermutlich mehrere solcher Fälle auftreten. Obwohl sie einen Einfluss auf die Gesamtprozentzahl haben, haben sie aber keinen oder nur geringen Einfluss auf den anschließenden Vergleich der Systeme, da alle Systeme durch die selbe Person evaluiert wurden und somit nach den selben Kriterien des Testers bewertet wurden. Die Testdaten und Bewertungen sind in dem elektronischen Anhang aufzufinden.
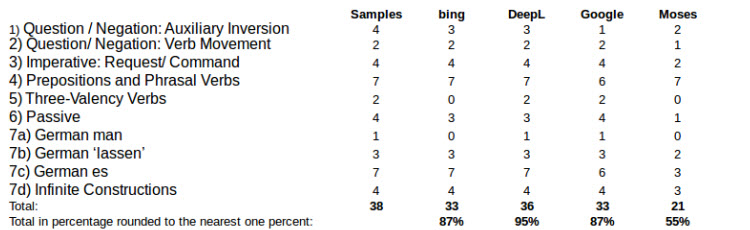
Tabelle 6: Benchmark Test DE-EN Teil1
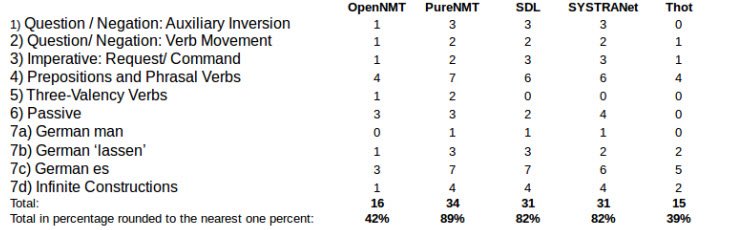
Tabelle 7: Benchmark Test DE-EN Teil2
Oben ist die Zusammenführung des beschriebenen Two Scale Ratings für die Übersetzung in Richtung Englisch aus dem Deutschen und unten für das sprachliche Gegenpaar. Sie zeigt, dass Thot besonders schlecht abschneidet , OpenNMT und Moses jedoch auch nicht weit entfernt sind. PureNMT, SDL, SYSTRANet, Microsoft und Google Übersetzer liegen zwischen 80% und 90% und somit in einem Bereich der guten Qualität. Eine bessere jedoch liefert Deepl mit 95% der zu erreichenden Punkte. Eindeutige systemübergreifende Fehlerquellen sind nicht erkennbar.
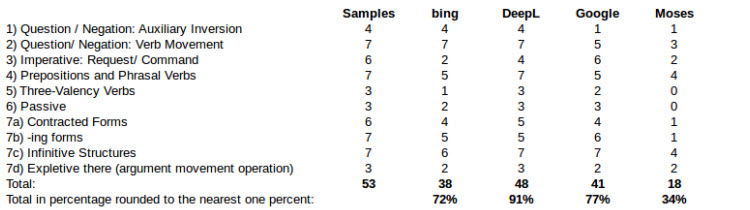
Tabelle 8: Benchmark Test EN-DE Teil1
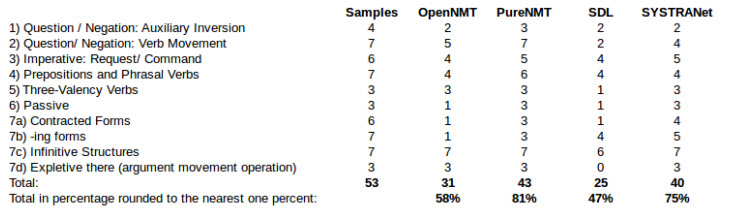
Tabelle 9: Benchmark Test EN-DE Teil2
Die Tatsache die in dieser Tabelle als erstes ins Auge springt, ist das Fehlen des Übersetzers Thot. Um eine genaue Erklärung für dessen Fehlen an dieser Stelle zu erhalten, kann der Abschnitt zu diesem Übersetzer im vorherigen Kapitel gelesen werden, weswegen auch nicht weiter darauf eingegangen wird und dieser Hinweis nicht ein weiteres Mal eingefügt werden wird. Die Tabelle zeigt außerdem, dass Moses in diesem Experiment am schlechtesten abschneidet. SDL und OpenNMT zeigen jedoch auch keine guten Ergebnisse. Das Mittelfeld belegen mit etwa zwischen 70% und 80% die MÜ-Systeme SYSTRANet, PureNMT, Google und Microsoft Übersetzer. DeepL erzielt wiederholt das beste Ergebnis, diesmal mit 91%. Generell fällt auf, dass die Ergebnisse in dieser Übersetzungsrichtung schlechter ausfallen. Zudem fällt eine gemeinsame Schwäche auf: Das Erkennung beziehungsweise die Umsetzung des Imperativs.

Tabelle 10: Benchmark Test Übersicht
Zusammenfassend ist festzuhalten, dass die Übersetzungen von Deutsch nach Englisch besser sind als von Englisch nach Deutsch. Die einzige Ausnahme zu der Regel macht OpenNMT. Der beste maschinelle Übersetzer über beide Sprachen ist mit einem klaren Abstand von im knappsten Fall 8% DeepL. Die schlechtesten Ergebnisse produziert, neben Thot, welcher wegen der Fehlenden Übersetzung nach Deutsch nicht direkt in diesen Vergleich eingebunden werden darf, der Open-Source-Übersetzer Moses. Generell muss festgehalten werden, dass selbst mit Einbeziehung des "verfälschten" Thot-Werts, die durchschnittliche Übersetzungsqualität klar über 50% liegt.
5.1.3 Auf Fehlerzählen basierende Test Suite
Im Prinzip ist eine Test Suite Evaluation eine in einen Kontext eingebettete Evaluation durch Fehlerzählen. In einem Test Suite soll die Verständlichkeit beziehungsweise die Leserlichkeit des übersetzten Textes getestet werden. Durch die Präsentation der Fehlerzähl-Ergebnisse in Tabellen wird der Fokus auf eben dieses Merkmal gelegt. [Schwarzl 2001: 168] Zum Fehlerzählen wird die Error Classification Table (ECT) aus [Schwarzl 2001: S.152] verwendet, sie ist im elektronischen Anhang anzusehen. Je niedriger hier das Ergebnis, desto höher ist die Übersetzungsqualität. [Schwarzl 2001: 168] Es wurden pro maschinellem Übersetzersystem 20 Sätze bewertet, wobei die ersten 10 aus einem formalen Kontext stammen und die restlichen 10 aus der Umgangssprache. Die Bewertung fand wegen des hohen Aufwands exemplarisch lediglich mit den Übersetzungen von Deutsch nach Englisch statt.
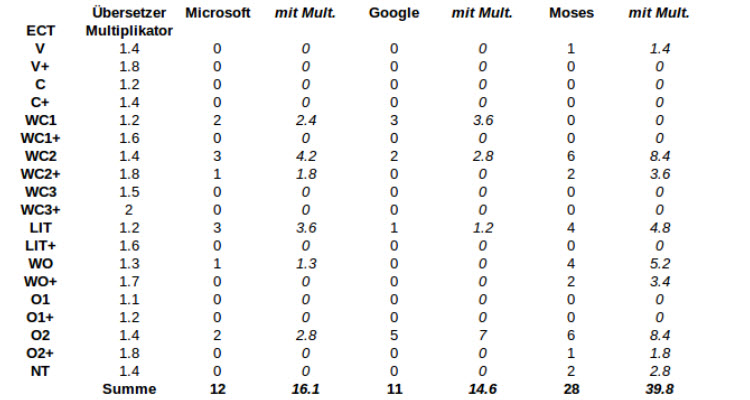
Abbildung 1: Test Suite Teil1
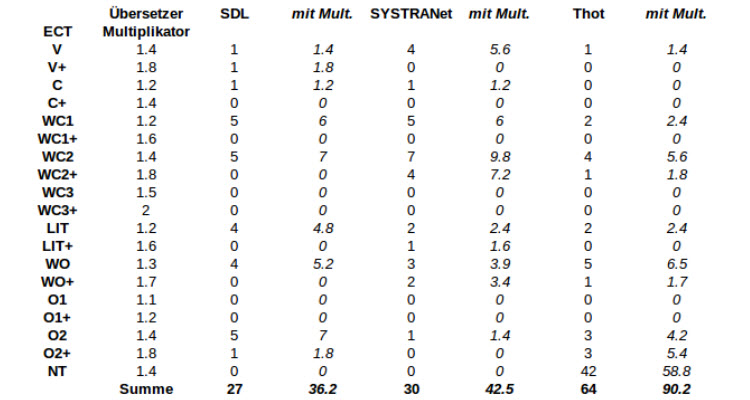
Abbildung 2: Test Suite Teil2
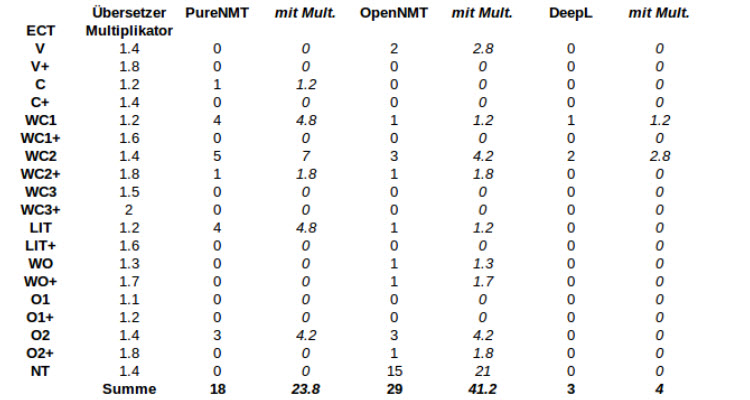
Abbildung 3: Test Suite Teil3
Mit Abstand am schlechtesten schneidet Thot ab, doch dies erscheint nach den inzwischen vorgestellten Ergebnissen nicht überraschend. Und die Tatsache, dass dieses MÜ-System hauptsächlich Fehlerpunkte wegen Vokabellücken sammelt unterstreicht den Fakt, dass Thot mit den geringsten Daten trainiert wurde. Würde man diesen Punkt jedoch ignorieren, könnte sich dieser Übersetzer mit seinen Konkurrenten messen. SYSTRANet, OpenNMT, Moses und SDL bilden das restliche Schlusslicht. Die Fehlertypen stimmen weitgehend überein. Sie alle machen viele Ausrucksfehler (WC2) und vergessen manchmal ein Wort zu übersetzen (O2). Alle außer OpenNMT übersetzen manchmal wörtlich (LIT) und bringen manchmal die Wortstellung durcheinander (WO). Die drei durchschnittlichen Systeme sind Microsoft Übersetzer, Google Übersetzer und PureNMT. Sie weisen alle Probleme in der Wortwahl auf. Sie machen jedoch nicht nur grobe Ausdruckfehler (WC2), wie die vorher erwähnten Systeme, sondern manchmal nur leichte (WC1), den Stil betreffende. Sie zeigen auch Schwächen bei der Wortstellung (LIT) und vergessen ebenfalls Wörter (O2). Generell ist die Fehlerdichte jedoch geringer. Das am besten abschneidende MÜ-System ist mit nur drei Fehlern DeepL. Diese wenigen Fehler verteilen sich auf einen schwachen Ausdruckfehler (WC1) und zwei starke (WC2).
5.2 Maschinelle Evaluation
Die Maschinellen Evaluationsmethoden wurden nur in die Richtung Deutsch – Englisch durchgeführt. Auf einen Vergleich der Ergebnisse mit der Orientierung Englisch – Deutsch wird verzichtet. Diese Entscheidung wurde getroffen, um die Einbindung aller Übersetzersysteme zu ermöglichen und den Thot Übersetzer nicht zu benachteiligen. Maschinelle Evaluierung zeichnet sich durch die Objektivität der Bewertungen aus. Jedoch darf die Objektivität nicht als Garant genommen werden für die Übereinstimmung der gegebenen Bewertung mit der tatsächlichen Qualität. Um dieser Nahe zu kommen, müssen die Werte trotz allem im Kontext der Entstehung betrachtet werden.
5.2.1 BLEU
BLEU steht für Bilingual Evaluation Understudy und ist seit circa 15 Jahren ein etabliertes Maß. [Papineni 2002:1] Es ist eine der verbreitetsten und simpelsten Methoden der Evaluation maschineller Übersetzung. Grundprinzip ist der Vergleich der maschinengefertigten Übersetzung mit der eines professionellen menschlichen Übersetzers über einen geometrischen Mittelwert der Korrespondenz der n-Gramme der verglichenen Texte. [EuroMatrix 2007: 51f] Die möglichen resultierenden Ergebnisse befinden sich zwischen 0 und 1, während 0 für "gar keine Ähnlichkeit" und 1 für "die Texte sind identisch" steht. Bei der Bewertung der Ergebnisse ist deswegen zu beachten, dass normalerweise selbst Übersetzungen durch einen Menschen nicht den Höchstwert erzielen. [Papineni 2002: 5] Die Evaluation wurde drei Mal durchgeführt, einmal mit Hilfe des MTEval Toolkits [Oda 2017], ein anderes mal durch ein BLEU-EvaluationsModul in NLTK [Bird u.a. 2009] in dem Python-Skript "eval_bleu.py", welches in dem elektronischen Anhang genauer betrachtet werden kann und ein drittes mal mit der Implementation eines Software namens MultEval, welche eigentlich zur Kontrollierung von Optimisierer Instabilität gedacht ist. [ Clark u.a. 2011]

Abbildung 4: BLEU Teil1

Abbildung 5: BLEU Teil2
Die Tabelle zeigt auf den ersten Blick vor allem die große Divergenz der Ergebnisse zwischen den unterschiedlichen Programmen. Zwar wird es nicht angegeben, doch ist anzunehmen, dass die MultEval-Werte in Prozent angegeben sind, wodurch sich die Werte in der "BLEU_MULTEval_normal" Zeile ergeben. Doch auch nach dieser Normalisierung stimmen die Werte der unterschiedlichen Übersetzer nicht überein und bilden auch keine identische Tendenz ab. Deswegen wurde der Durchschnitt der Werte BLEU_MTEval, BLEU_NLTK und BLUE_MULTEval_normal" genommen. Dieser Mittelmaß suggeriert dass Microsoft Übersetzer und DeepL zusammen mit SDL die beste Übersetzerqualität bieten und Google Übersetzer und Moses die schlechteste. ONMT, PNMT, SYSTRANet und Thot fallen ins Mittelfeld.
5.2.2 METEOR
Meteor ist der direkte "Konkurrent" des BLUE Maßes, da diese Evaluationsmethode entwickelt wurde um die Schwächen seines Vorgängers direkt zu adressieren. [EuroMatrix 2007: 53] Meteor basiert in seiner aktuellen Version auf dem Vergleich der Musterübersetzung mit den generierten maschinellen Übersetzungen auf Satzlevel, wobei die beinhalteten Wörter exakt, nach dem Stamm, nach Synonymen und nach Paraphrasen verglichen werden. [Denkowski und Lavie 2014: 1] Die tatsächlichen Berechnung des Wertes im Anschluss basiert auf einer normalisierten und gewichteten Variante des parametrisierten harmonischen Mittel von Precision und Recall, welche bezüglich der Unigrammhäufigkeiten berechnet wird. [EuroMatrix 2007: 54] Neben der offiziellen Implementierung [Denkowski und Lavie 2014] wurde ebenfalls eine Meteor Evaluation mit MultEval durchgeführt. [Clark u.a. 2011] Die ausführliche Version der Meteor-Daten des Originalprogramms ist im Anhang aufzufinden.[A1]
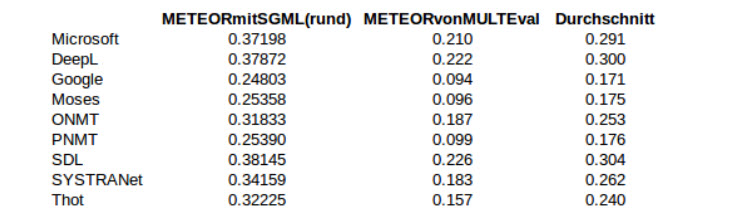
Abbildung 6: METEOR Übersicht
Da auch hier die ursprünglichen Ergebnisse nicht korrelierten, wurde genauso wie bei der Betrachtung der BLEU-Evaluationsmethode pro maschineller Übersetzer das arithmetische Mittel der Werte der Evaluationsprogramme gebildet. Daraus lässt sich leiten, dass SDL, DeepL und der Microsoft Übersetzer die besten Resultate liefern, während der Google Übersetzer gemeinsam mit Moses und PNMT die Übersetzungen mit der schlechtesten Qualität produziert.
5.2.3 NIST
NIST steht für Nation Institute for Standards and Technology und der Name beschreibt eine Evaluationsmethode, welche BLUE sehr ähnlich ist, im Sinne der Sammlung von n-Gramm Häufigkeiten zur Bestimmung der Übersetzungsqualität, wobei der signifikanteste Unterschied die Gewichtung der n-Gramm-Genauigkeiten durch die n-Gramm-Häufigkeiten um die seltenen Sequenzen zu betonen ist. [EuroMatrix 2007: 65] Der Ergebniswert ist jeweils, wenn nicht normalisiert durch eine Division durch das größte zu erreichende Ergebnis, eine reelle Zahl größer 0. [Sugiyama u.a. 2015: 4] Die Evaluation wurde mit Hilfe des Programms MTEval durchgeführt. [Oda 2017] Durch das Einfügen des Referenzdatensatzes als zu evaluierende "Übersetzung" entsteht ein NIST Maximalwert von gerundet 11,4. Damit wurden die Ergebniswerte, wie in nachfolgender Tabelle einsehbar, normalisiert.

Abbildung 7: NIST Übersicht
Da große Werte für eine große Qualität stehen, zeigt die Aufzählung der MTEval-Ergebnisse DeepL und dem SDL Übersetzer als Spitzenreiter der verglichenen Systeme. Moses wird mit einem Wert von gerundet 0.16, normalsiert sogar nur 0.01, die niedrigste Qualität zugesprochen.
5.2.4 RIBES
RIBES ist ein maschinelles Evaluationsmaß, welches den Unterschied der in der Übersetzung aufgefundenen Syntax zur korrekten Wortstellung beschreibt, wobei 0 der schlechteste und 1 der bestmöglich zu erreichende Wert ist. [Sugiyama u.a. 2015: 4] Das MTEval Toolkit [Oda 2017] hat für die betrachteten Systeme folgende Ergebnisse geliefert:

Abbildung 8: RIBES Übersicht
Wie schon bei anderen Evaluationsmethoden beobachtet, erzielen auch hier die Übersetzer von DeepL und SDL die besten Resultate. Die Microsoft, Google und Thot Übersetzer sind jedoch auch nicht fern von der Spitze. Mit Abstand am schlechtesten schneidet wiederholt Moses ab.
5.2.5 WER
WER steht für Word Error Rate, also Wortfehlerrate, und beschreibt die minimale Menge an Bearbeitungsschritten auf Wortlevel von der betrachteten maschinellen Übersetzung zur angenommen optimalen, menschlichen Übersetzung dieses Texts. [EuroMatrix 2007: 55] Das WER-Maß kann, nicht wie bei WERg durch eine besondere normalisierte Version der Bewertungsmethode, einen Wert zwischen 0, also keine Bearbeitungen nötig und x, der Bearbei tungszahl dividiert durch die Länge des Referenzsatzes, einnehmen, wodurch auch ein Wert größer 1 entstehen kann. [EuroMatrix 2007: 55] Da es eine Fehlerrate ist, darf nicht vergessen werden, dass ein größerer Wert eine schlechtere Qualität bedeutet, und wenn diese Eigenschaft unerwünscht ist, ist eine Bedeutungsumdrehung durch Subtraktion von 1 möglich, was jedoch bei den Ergebnissen der Evaluation mit dem MTEval Toolkit [Oda 2017], welche durchgeführt wurde, nicht getan wurde.

Abbildung 9: WER Übersicht
Die Tabelle zeigt die niedrigsten, also besten WER-Werte für die Übersetzungen erstellt von DeepL und SDL. Das schlechteste Ergebnis erzielt PNMT. Ebenfalls schlechte Werte zeigen Moses und Google Übersetzer, jedoch sind diese nicht so extrem wie des "Verlierers" der Evaluation.
5.2.6 TER
TER [Snover u.a. 2006] steht für Translate Error Rate, also Übersetzungsfehlerrate, und eine sehr leicht nachvollziehbare maschinelle Evaluationsmethode, da das Maß die Anzahl an Bearbeitungen repräsentiert, die nötig sind um eine maschinelle Übersetzung so durch Einfügungen, Löschungen, Ersetzungen und Verschiebungen zu ändern, dass sie der menschlichen Übersetzungsreferenz entspricht, normalisiert durch die Länge der Referenzen. [EuroMatrix 2007: 56] Dabei unterscheidet sich TER von WER besonders darin, dass zusammenhängende Wortsequenzen als eine einzelne Handlung aufgefasst werden. [EuroMatrix 2007: 56] Die Evaluierung wurde durch zwei Programme vollzogen. Eines dieser Programme ist die originale TER-Software "Tercom" [Snover u.a. 2006]. Gespeist wurde das Programm mit den Daten im SGML-Format, welche schon bei der Meteor Evaluierung genutzt wurden. Die Ergebnisse wurden in folgender Tabelle zusammengefasst:
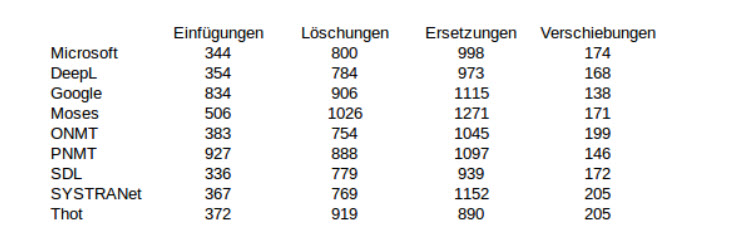
Abbildung 10: TER Teil1
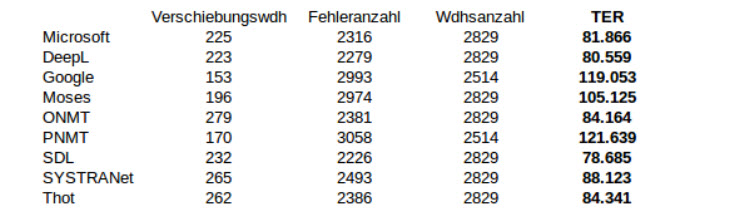
Abbildung 11: TER Teil2
Die Ergebnisse zeigen dass für die von Google und PNMT erstellten Übersetzungen besonders viele Einfügungen benötigt waren um die Texte zu der Referenz umzuwandeln. Aus der Übersetzung von Moses mussten die meisten Wörter gelöscht werden. Ersetzt musste bei allen Systemen außer dem Thot Übersetzer sehr viel. Die wenigsten Verschiebungen benötigte der Google Übersetzer, die meisten SYSTRANet und Thot. Auffällig ist außerdem der Zusammenhang, dass eine geringere Wiederholungsanzahl zu einer erhöhten Fehleranzahl führt.
Die andere verwendete Evaluierungssoftware ist das in dieser Arbeit inzwischen des öfteren erwähnte MultEval. Da dieses Programm weniger ausführliche Evaluationsdetails angibt, werden diese wenigen Werte, anstatt sie separat zu betrachten, mit einer simplifizierten Version der vorherigen Ausführung verglichen.

Abbildung 12: TER Übersicht Teil1

Abbildung 12: TER Übersicht Teil2
Die Werte der zwei Evaluationsprogramme in diesem Experiment divergieren nicht so sehr wie in einigen vorherigen Abschnitten beobachtbar. Die vorhandenen Unterschiede resultieren voraussichtlich aus dem Nutzen von nicht im Voraus bearbeiteten Test- und Übersetzungsdaten, welche MultEval akzeptiert, Tercom jedoch nicht, weswegen dafür die SGML-Daten verwendet wurden. Vor der genaueren Betrachtung der Ergebnisse wurde zusätzlich der Durchschnitt der Werte pro maschinellem Übersetzer berechnet, um eine bessere Übersicht zu erhalten. MultEvals Verlierer und Sieger stimmen mit denen Tercoms überein. Deswegen kann zusammenfassend gesagt werden, dass die WER-Methode SDL, Microsoft und DeepL die höchste Qualität zusagt und Google und PNMT die niedrigste.
5.3 Zusammenfassende Betrachtung der Evaluationsergebnisse
Um diese Ergebnisse mit anderen zu vergleichen, darf nicht vergessen werden, dass alle maschinellen Evaluationen in dieser Arbeit auf nur einer Übersetzungsreferenz basieren und erst ab vier eine signifikante Unterscheidung guter von schlecher Übersetzung sinnvoll möglich ist. [EuroMatrix 2007: 66] Da es jedoch den Rahmen dieser Arbeit gesprengt hätte drei Alternativübersetzungen zu der vorliegenden Europarl "Übersetzung", also den Paralleldaten des Korpus, anzufertigen bzw. anfertigen zu lassen, konnte dieser Umstand nicht verhindert werden und somit dürfen die Ergebnisse nur in diesem Kontext betrachtet werden. Außerdem führt diese Tatsache zu generell niedrigeren Evaluationswerten bei allen Systemen. [EuroMatrix 2007: 66] Um dieses Problem zu umgehen, wird diese Zusammenfassung auf die in den vorherigen Abschnitten herausgearbeiteten Gewinner und Verlierer beziehen und nicht auf konkrete erzielte Werte.
Eine Tatsache, die sofort ins Auge springt, ist die starke Divergenz der Gewinner und Verlierer zwischen manueller und maschineller Evaluation. Wobei die Verlierer die größte Distanz aufweisen. Der offensichtliche Verlierer der manuellen Bewertung ist ohne Frage Thot. Mit größeren, besseren aufbereiteten Trainingsdaten, sowie besserer Hardware oder mehr Zeit könnte dieses MÜ-System definitiv mithalten, da dies jedoch nicht die Experimentbedingungen waren, bleibt es der Verlierer bei der manuellen Evaluation. Der Hinweis darauf, dass das System nicht so schlecht ist, wie es scheint, ist die Tatsache, dass es bei den maschinellen Evaluationsmethoden kein einziges Mal zu den Verlierern gehörte. OpenNMT stellt einen besonderen Fall dar, da es bei der manuellen Evaluation in einer Teilbewertung mit an erster Stelle steht, und in der selben Evaluationsart einer der Verlierer ist. Gewinner ist es bei dem Four Scale Rating bei dem formalen Text auf Englisch, Verlierer bei dem gleichen Experimentaufbau bei dem umgangssprachlichen englischen Text. Ähnliches widerfährt auch dem Google Übersetzer. Dieser ist bei der maschinellen Bewertung drei mal Verlierer, wird in der manuellen Evaluation jedoch als Gewinner aufgezählt. PureNMT liefert ebenfalls drei Mal keine Übersetzung in passabler Qualität ab, jedoch liefert es keine Spitzenwerte wie der Google Übersetzer. Der einzige Verlierer der manuellen Evaluation, welcher ebenfalls bei der maschinellen Bewertung als Verlierer gesehen wird ist Moses. Mit insgesamt 5 klaren Auszeichnungen als schlechtester Übersetzer bei den Evaluationsmethoden Benchmark Test, BLEU, METEOR, NIST und RIBES kann es als das am wenigsten zu weiterempfehlende MÜ-System bewertet werden. Wichtig ist aber dabei, dass dieses System, obwohl es als "das Schlechteste" bewertet wurde, nicht zu vergessen, dass es trotzdem gute Ergebnisse liefert. Keiner der Übersetzer war bei jeder Bewertungsmethode das Schlusslicht, sondern lieferte bei mindestens fünf anderen Evaluationsarten passable Werte ab.
Bei den Gewinnern ist eine ähnliche Diskrepanz zwischen manueller und maschineller Bewertung zu verzeichnen. Es gibt einen klaren – in dem Fall – Sieger und einige separate Erstplatzierte. Einer der nicht übereinstimmenden Gewinner ist der Google Übersetzer. Denn diesen Titel trägt er bloß bei dem Four Scale Rating. Den Microsoft Übersetzter trifft ein ähnliches Schicksal bei der maschinellen Evaluation. Er ist Sieger bei BLEU, METEOR und TER, jedoch nie alleiniger. Bei jedem maschinellen Bewertungstypen als Sieger beteiligt ist SDL. Somit ist es zusammen mit DeepL Sieger der maschinellen Übersetzung. Doch das eben erwähnte DeepL erzielt nicht nur Topwerte bei der maschinellen Evaluation, sondern ist auch klarer Sieger der manuellen Beurteilung. Damit ist dieses MÜ-System, laut der in dieser Arbeit unter den beschriebenen Umständen durchgeführten Evaluation, das beste.
Eine weitere Untersuchung der Ergebnisse zeigt, dass die Open-Source-MÜSysteme, abgesehen von dem oben erwähnten merkwürdigen Verhalten von OpenNMT, nicht in den Siegerreihen vertreten sind. Bei der manuellen Evaluation sind sie gar allesamt Verlierer. Die freien Onlinedienste überzeugen gleichermaßen bei beiden Evaluationsprozeduren beziehungsweise um genau zu sein bei exakt allen Evaluationsarten.
6 Abschließende Gedanken
Am Ende dieser Arbeit konnte sich ein MÜ-System zwischen den anderen Durchsetzen. Dieses war der freie Onlinedienst DeepL. Dieser steht zugleich für den Sieg der freien online Systeme über die Open-Source-MÜ-Systeme. Dieses Resultat war durchaus vorauszusehen und man hätte durch viel Aufwand und Anpassungen der Einstellungen mit diesen Systemen eventuell auch bessere Ergebnisse erzielen können. Doch das Ziel war unter anderem herauszufinden, was für Ergebnisse die Systeme "out of the box" bieten. Außerdem bestand der Hauptsinn der Arbeit nicht aus dem Auffinden des besten Systems, sondern der Einführung in die Forschung und Anwendung der maschinellen Übersetzung. Wichtig war also neben dem Aufzeigen der Entstehungsgeschichte der maschinellen Übersetzer, eine Einführung in einzelne Systeme zu geben und die möglichen Evaluationsmethoden zu erproben. Im Laufe dieser Arbeit mussten viele am Anfang geplanten maschinellen Übersetzer aussortiert werden, da eine Themenbegrenzung nötig war um den Überblick zu wahren. Aus dem selben Grund wurde auch nur ein Teil der möglichen Evaluationsmethoden getestet. Die Vervollständigung durch alle Systeme und Methoden wären interessante weiterführende Arbeiten, obwohl es zu bezweifeln ist, ob eine Person in der Lage ist das heutige Bild des Zustands der maschinellen Übersetzung vollständig einzufangen, ohne dass der Fortschritt die Arbeit irrelevant werden lässt. Der Trend weiterer neuerer und besserer MÜ-Systeme wird sich noch eine Weile fortführen, da das Gebiet der neuronalen maschinellen Übersetzung erst langsam für sich gefunden wird und das Verlangen des Menschen nach einem Weg die Sprachbarriere zu durchbrechen nicht erlischt bis das perfekte System erschaffen wurde oder ein unüberwindbarer Punkt der Stagnation erreicht wurde. Doch selbst dann würde man versuchen durch andere Wege, wie interdisziplinäre Inspiration, die bestehenden Programme zu verbessern. Wie man sieht, bietet dieses Gebiet viel Raum für Verbesserung und Forschung, doch genauso wichtig ist eine umfassende Dokumentation und Strukturierung bestehender Systeme. Interessant wäre eine allumfassende Liste bestehender, gepflegter MÜ-Systeme, die es momentan auf der Welt gibt. Von Interesse dabei sind vor allem Open-Source-Angebote, da diese offene Forschungsarbeit und Fortschritt erlauben.
Literaturverzeichnis
Bahdanau, D., Cho, K. und Bengio Y. 2015. Neural machine translation by jointly learning to align and translate. ICLR.
Bing. 2017. Bing Übersetzer. "https://www.bing.com/translator" Abrufdatum 25.09.2017.
Bird, S., Klein, E. and Loper, E. 2009. Natural language processing with Python: analyzing text with the natural language toolkit. " O'Reilly Media, Inc.".
CharacterCountOnline. 2017. Online Character Count Tool. "http://www.charactercountonline.com/" Abrufdatum 25.09.2017.
Clark, J.H., Dyer, C., Lavie, A. and Smith, N.A. 2011, June. Better hypothesis testing for statistical machine translation: Controlling for optimizer instability. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: short papers-Volume 2 (pp. 176-181). Association for Computational Linguistics.
De Gispert, A., Iglesias, G. and Byrne, B. 2015, January. Fast and accurate preordering for SMT using neural networks. In: NAACL HLT 2015-2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference (pp. 1012-1017).
DeepL. 2017a. DeepL Translator. "https://www.deepl.com/translator" Abrufdatum 25.09.2017.
DeepL. 2017b. DeepL Press. "https://www.deepl.com/press.html" Abrufdatum 25.09.2017.
Denkowski, M. and Lavie, A. 2014. Meteor universal: Language specific translation evaluation for any target language. In: Proceedings of the ninth workshop on statistical machine translation (pp. 376-380).
EuroMatrix. 2007. 1.3: Survey of machine translation evaluation. In: EuroMatrix Project Report, Statistical and Hybrid MT between All European Languages, co-ordinator: Prof. Hans Uszkoreit.
Hutchins, W.J. 1986. Machine translation: past, present, future. Chichester: Ellis Horwood.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics(ACL '02). Association for Computational Linguistics, Stroudsburg, PA, USA, 311-318.
Klein, G., Kim, Y., Deng, Y., Senellart, J. and Rush, A.M. 2017. OpenNMT: Open-Source Toolkit for Neural Machine Translation.
Koehn, P. 2005, September. Europarl: A parallel corpus for statistical machine translation. In: MT summit (Vol. 5, pp. 79-86).
Koehn, P. 2011. Machine Translation System User Manual and Code Guide.
Lison, P. and Tiedemann. J. 2016, May. OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In: LREC. -> Sammlung von Texten von http://www.opensubtitles.org/
Luckhardt, H.D. und Zimmermann, H.H. 1991. Computergestützte und maschinelle Übersetzung: praktische Anwendungen und angewandte Forschung. AQ-Verlag.
Machine Translation Group. 2017. Moses Online MT Demo. "http://demo.statmt.org/" Abrufdatum 18.09.2017.
Microsoft. 2017. Machine Translation - Microsoft Translator. "https://www.microsoft.com/en-us/translator/mt.aspx" Abrufdatum 25.September 2017.
Oda, Y. 2017. "https://github.com/odashi/mteval" Abrufdatum 26.09.2017.
Opensource. 2017. What ist open source? "https://opensource.com/resources/what-open-source" Abrufdatum 25.09.2017.
Ortiz-Martínez, D. and Casacuberta, F. 2014, April. The New Thot Toolkit for Fully-Automatic and Interactive Statistical Machine Translation. In: EACL (pp. 45-48).
Quoc V. Le & Mike Schuster. 2016, September. A Neural Network for Machine Translation, at Production Scale. In: Google Research Blog. Google. Abrufdatum 25.09.2017.
Schwanke, M. 1995. Maschinelle Übersetzungssysteme. I & F Verlag.
Schwarzl, A. 2001.The (im) possibilities of machine translation(Vol. 381). Peter Lang Pub Inc.
SDL. 2017. FreeTranslation.com. "https://www.freetranslation.com/" Abrufdatum 25.09.2017.
SDL Plc. 2017. Research | SDL. "http://www.sdl.com/software-and-services/research/" Abrufdatum 25.09.2017.
Snover, M., Dorr, B., Schwartz, R., Micciulla, L. and Makhoul, J. 2006, August. A study of translation edit rate with targeted human annotation. In: Proceedings of association for machine translation in the Americas (Vol. 200, No. 6).
Stein, D. 2009. Maschinelle Übersetzung-ein Überblick. JLCL, 24(3), pp.5-18.
Statmt. 2012. Europarl Parallel Corpus. "http://www.statmt.org/europarl/" Abrufdatum: 25.09.2017.
Sugiyama, K., Mizukami, M., Neubig, G., Yoshino, K., Sakti, S., Toda, T. and Nakamura, S. 2015, September. An Investigation of Machine Translation Evaluation Metrics in Cross-lingual Question Answering. In: WMT@ EMNLP (pp. 442-449).
SYSTRAN. 2017a. SYSTRANet – Online translation software and tools – Text translation. "http://www.systranet.com/translate" Abrufdatum 25.09.2017.
SYSTRAN. 2017b. SYSTRAN Hybrid Technology | SYSTRAN – Translation Technologies. "http://www.systransoft.com/systran/translation-technology/systran-hybrid-technology/" Abrufdatum 25.09.2017.
SYSTRAN. 2017c. Pure NeuralTM Machine Translation | SYSTRAN – Translation Technologies. "http://www.systransoft.com/systran/translation-technology/pure-neural-machine-translation/" Abrufdatum 25.09.2017.
SYSTRAN. 2017d. Pure NeuralTM Machine Translation demonstrator. "https://demo-pnmt.systran.net/production#/translation" Abrufdatum 25.09.2017.
Wilss, W. 1987. Theoretische Aspekte der Maschinellen Übersetzung. Maschinelle Übersetzung–Methoden und Werkzeuge.–Tübingen: Niemeyer (pp.1-14).
Anhang
[A1]
|

